이전에 알아본 최소제곱법을 이용한 예측선을 만드는 선형회귀방법에서는, 독립변수(x)가 한 개 였기때문에 큰 문제가 없었으나, x가 여러개로 늘어나게되면 식이 점차 복잡해져 계산에 무리가 가게된다.
2022.06.22 - [파이썬(Python), 머신러닝, 딥러닝] - 딥러닝 기초 - (2)선형회귀(최소제곱법) - 파이썬으로 코딩
딥러닝 기초 - (2)선형회귀(최소제곱법) - 파이썬으로 코딩
이번 포스팅에서는 파이썬을 통해서 선형회귀를 실습해보겠다. 1. 최소제곱법(Least Square Method) 파이썬으로 실습하기 (1) Numpy 라이브러리 불러오기 * Numpy : 행렬이나 일반적으로 대규모 다차원
goodsarah.tistory.com
특히나, 딥러닝의 경우 많은 양의 변수를 처리하며, 그 변수들을 변형하여 더 많은 변수들을 만들어 내기에 엄청나게 많은 변수들이 분석에 사용되게 됩니다. 이러한 경우에 계산을 효율적으로 할 수 있는 방법이 있는데 그 중 하나가
평균제곱오차(Mean Squared Error) 를 사용하는 것이다.
1.평균제곱오차(Mean Squared Error)란?
평균제곱오차란, 추정된 값과 실제 값 간의 차이에 제곱을 한 값의 평균을 구하는 방법을 말한다.
식으로 표현해보면, 아래와 같다

이때 n은 전체 데이터의 개수를 의미하며, y는 실제 값을, y hat은 추정된 값을 의미한다.
지난번에 알아본 최소제곱법과 비슷해보이지만, 문제를 풀어가는 방식이 다르다.
최소 제곱법은 위 식 (1)에서 각 y와 y hat을 x에 대해 정리하여 미분하여 최소값을 구하는 방법이었으나,
평균제곱오차는,
a)최초에 임의의 회귀선을 준 다음 오차의 제곱의 평균을 구하고,
b)이후 기울기와 절편을 조금씩 수정하여 오차의제곱의 평균을 구한 뒤
a)와 b)를서로 비교하여 더 작은 값을 취하는 방식을 택하고 있다.
기울기와 절편의 값을 조절하고, 계산해서 비교하고, 더 작은 값을 취해가는 방식이기에 계산이 덜 복잡하다는 장점이 있으며,
선형회귀가 아닌 다른 회귀방법에서도, 회귀식이 가지고 있는 변수(Parameter)들 값들만 바꿔가며 오차의 제곱의 평균을 비교하면 되기에 많이 사용되고 있다.
*나중에 다루겠지만, 이를 Parameter tuning 이라고 한다.

최소 제곱법에 비해서 평균 제곱오차가 가지고 있는 단점은, 조금 덜 정확할 수도 있다는 점이다. 임의로 기울기와 절편을 수정해나가기에, 식으로 정리된 최소제곱법보다는 오차값이 조금 클 수도 있다.
Ex) 기울기를 1단위로 조정해나가는 것 보다는 0.1단위로 조정해나가는 것이 더 정확. 0.01 단위가 더 정확하며 ...... -> 촘촘하게 조정 단위를 설정해나갈수록 더 정확 But, 수식적으로 계산되는 딱 떨어지는 최적의 값을 찾지 못할 수도 있음(조정 단위가 크거나, 수식적으로 계산된 값이 무한 소수인 경우)
하지만, 변수의 개수가 늘어나고, 입력된 데이터들의 개수가 늘어날수록 계산의 복잡도가 너무 심해져 계산기에 부하를 주고 식을 도출하는 시간도 오래 걸리기에 평균제곱오차를 많이 사용한다.
개념은 이정도로 알아보고, 파이썬 코드를 실행하여 직접 구현을 해보자.
2. 파이썬 실습(평균제곱오차 / Mean Sqaured Error)
(1) Numpy 라이브러리 및 실습에 사용할 데이터 생성
#Numpy library 불러오기
import numpy as np
# x = 키 / y = 몸무게 로 정의하여 여러개의 관측값을 만든다.
x=np.array([180, 170, 175, 165, 193, 177, 181, 169, 163])
y=np.array([70, 63, 67, 70, 80, 61, 79, 69, 59])
# .pyplot 라이브러리를 통한 데이터 시각화 (Scatter plot)
import matplotlib.pyplot as plt
plt.xlabel('Height')
plt.ylabel('Weight')
plt.scatter(x,y)
plt.show()
(2) 최초 입력값으로 들어갈 회귀선 생성 (회귀선 : y = ax + b)
# 분석을 위해 최초로 설정하는 추정 회귀선의 기울기를 1, y 절편을 10으로 선정
initial_a = 1
initial_b = 10
#함수식 정의
def predict(x):
return initial_a * x + initial_b
#위 코드의 결과값을 저장할 리스트 생성
predict_result = []
(3) 모든 x값을, 위에서 정의한 최초 회귀식에 대입하여 결과를 계산하는 predict() 함수 만들기
#모든 x값을 predict() 함수에 대입해 예측값 리스트를 채우는 코드를 생성
for i in range(len(x)):
predict_result.append(predict(x[i]))
print("신장 = %.f, 몸무게 = %.f, 예측 몸무게=%.f" %(x[i], y[i], predict(x[i])))
실제 몸무게와 예측 몸무게(최초 식에 대입되어 도출되는 값)과의 차이가 큰 것으로 보아, 평균제곱오차도 상당히 크게 나올 것으로 예측된다.
(4) 평균제곱오차(mse) 계산
n = len(x) #총 데이터의 개수(=x의 개수)
def mse(y, y_pred):
return sum((y-y_pred)**2)/n
print("평균 제곱 오차 :" + str(mse(y,predict_result)))
꽤나 큰 오차의 제곱의 평균이 나오게 되었다. 기울기 값과 절편 값을 변화하여 값을 계산해보자
(5) 입력값 변경 (a = 0.5 / b= 5)
#이번에는 a를 0.5감소 / b는 5감소 시켜보자
test1_a = 0.5
test1_b = 5
#함수식 정의
def predict(x):
return test1_a * x + test1_b
#위 코드의 결과값을 저장할 리스트 생성
test1_predict_result = []
#모든 x값을 predict() 함수에 대입해 예측값 리스트를 채우는 코드를 생성
for i in range(len(x)):
test1_predict_result.append(predict(x[i]))
print("신장 = %.f, 몸무게 = %.f, 예측 몸무게=%.f" %(x[i], y[i], predict(x[i])))
#평균제곱오차계산
n = len(x) #총 데이터의 개수(=x의 개수)
def mse(y, y_pred):
return sum((y-y_pred)**2)/n
print("평균 제곱 오차 :" + str(mse(y,test1_predict_result)))
확실히 첫번째(평균제곱오차 : 13520.xx) 보다 두번째(평균제곱오차 : 586.xx)의 평균 제곱 오차값이 줄어들었으며,
이를 통해, 첫번째 식보다 두번째 식이 더 데이터를 잘 설명한다고 할 수 있다.
시각화를 통해서 알아보자
(7) 데이터 및 회귀식 시각화
plt.xlabel('Height') #x축 이름
plt.ylabel('Weight') #y축 이름
#데이터 표시
plt.scatter(x,y, label='Data')
#회귀선 방정식 입력
plt.plot(x,1*x+10, label='1st trial', color ='red')
plt.plot(x,0.5*x+5, label='2nd trial', color ='blue')
plt.legend()#범례작성
plt.show()#그림 출력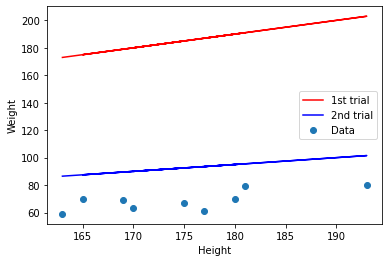
확실히 1번째 식은 데이터와 너무 동떨어진 y 절편을 가지고 있음이 보이며,
2번째 식은 데이터의 경향성과 어느정도 일치하는 기울기와, 그리고 아직도 차이가 많이 나지만 많이 가까워진 y절편을 가지고 있음을 확인할 수 있다.
그렇다면, 이렇게 a와 b의 값을 바꿔가면서 평균제곱오차를 최소하는 것을 수동으로 하나씩 해야할까?
당연히, 그렇지 않다.
a와 b에 들어갈 후보들은 선정하는 방법은, Grid_seacrh 와 Gradient descent(경사하강법)이 있다.
위 방법에 대해서는 다음 포스팅에서 알아보자
'파이썬(Python), 머신러닝, 딥러닝' 카테고리의 다른 글
| (파이썬 코드)다중퍼셉트론으로 XOR문제 해결하기 (0) | 2022.08.02 |
|---|---|
| 딥러닝 기초 - (4)선형회귀(경사하강법(Gradient descent) 사용) / 파이썬 코딩 (0) | 2022.06.22 |
| 딥러닝 기초 - (2)선형회귀(최소제곱법) - 파이썬으로 코딩 (0) | 2022.06.22 |
| 딥러닝 기초 - (1) 선형 회귀(Linear regression) 개념 (0) | 2022.06.21 |
| 딥러닝을 위해 필요한 3가지 (0) | 2022.06.11 |




댓글