지난 시간에 알아봤듯, 딥러닝은 머신러닝의 일부이며, 머신러닝의 가장 기초는 선형회귀에서부터 출발한다고 보면 된다.
대학에서 통계학 수업을 듣지않았다면 다소 생소할 개념일 수 있으나 쉽게 이해할 수 있는 내용이며,
예측이라는 분야에서 가장 기초이자 많이 쓰이는 내용이기에 필히 정리할 필요가 있다.
1. 선형 회귀란?
1) 선형회귀의 의미
선형 회귀(Linear Regression)란, 종속 변수 Y와 한 개 이상의 독립 변수(또는 설명 변수) X와의 선형 상관 관계를 모델링하는 회귀분석 기법으로 정의된다.
선형 회귀(Linear Regression)은 "선형(Linear)" 이라는 단어와 "회귀"라는 단어의 합성어로,
선형은 선(Line)이라는 의미이고, 회귀는 "제자리로 돌아간다"라는 의미로
X값(독립 변수들)이 변화함에 따라 변하게되는 Y값(종속변수)를 가장 잘 예측하는 선을 긋는 것을 의미합니다.
실제 세상에서는, 무수히 많은 변수들로 인해 예외가 종종 생기기도 하지만, 마치 연어가 고향으로 회귀하 듯 특정 X값에 대응하는 Y값도 특정한 값에 회귀하게 되고, 이렇게 모인 Y값들을 이어서 생기는 것이 선이되는 것입니다. 이 선을 우리는 회귀선이라고 부르는데요.

아래는 선형 회귀를 설명할 때 많이 쓰이는 키와 몸무게의 상관 관계를 나타내주는 그래프입니다.

우리는 많은 경험을 통해, 키가 클수록 몸무게가 많이 나간다는 사실을 오랜 시간동안 축적된 경험을 통해 알고 있습니다.
EX) 키 180의 한국 남자의 몸무게는 70 ~ 80kg 정도일 확률이 높다
위 결과는 우리가 경험한 많은 양의 데이터들이 우리 머리속에 축적이 되어, 키에 따른 몸무게의 추정치를 어느정도 예측할 수 있는 것이며, 각 몸무게별 가장 가능성이 높은 몸무게들을 선으로 연결한 것이 바로 "키(X)에 따른 몸무게(Y)를 나타내는 회귀선" 이라고 말하는 것입니다.
위 그림에서도 키와 사람들의 몸무게를 좌표평면에 표현한 뒤 가장 오차가 작은 선을 초록색으로 표현하였으며, 이것이 바로 회귀선이 되는 것입니다.
그렇다면, 위에서 설명한 "가장 오차가 작은 선"이란 무엇을 의미하는 것일까요?
2) 손실(Loss)과 최소 제곱법(Least Square Method)
먼저, 손실(Loss) 이라는 개념에 대해서 정의를 해보겠습니다. 여기에서 말하는 손실(Loss)란, 오차를 의미합니다.
즉, 특정 X값에 대응하는 회귀선 상의 Y' 값(= f(X) = aX + b ) 이 있을 것이고, 실제 Y값이 있을 것입니다.
여기서 손실(Loss)이란, Y(실제 값) 와 Y'(예측 값) 간의 차이를 의미하며, 이 차이는 특성에 따라 다양하게 정의가능합니다.
Ex) Y와 Y' 간의 차이의 절대 값, 나눈 값 등등...
선형회귀에서는 이 손실(Loss)를 정의하는 함수, 즉 손실함수(Loss function)을 표현하기 위해 최소제곱법을 사용하고 있습니다.
최소제곱법(Least Square)이란, 실제 Y값과 예측된 Y'값의 차이를 제곱한 값들의 최소값을 구하는 방법으로,


그래프 (b)처럼, 잔차(Residual = Y - Y')가 정사각형의 한변이 되는 정사각형들의 넓이의 최소값을 구하는 것과 같습니다.
이를 식으로 표현해보면 아래와 같은데요
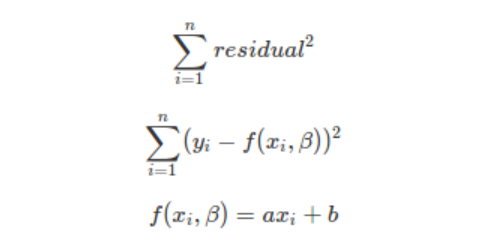
위 식에서 Residual은 Y - Y' , 즉 잔차를 의미합니다. 이때, 잔차(Residual)을 오차(Error)로 표현하지 않는 이유는 아래와 같은데요
** 오차(Error)는 모집단(즉, 해당 사건의 전체 사건)에서 추정된 회귀선에서 도출된 Y값과 관측치와의 차이를 의미하며
** 잔차(Residual)는 표본집단에서 추정된 회귀선에서 도출된 Y값과 관측치와의 차이를 의미하기에 차이가 있습니다.
** 즉, 회귀분석에 사용되는 관측치(데이터)들이 많아지면 많아질수록 잔차(Residual)는 오차(Error)에 가까워지게 되는 것입니다.
위 식 (1)에서 우리가 구하고자 하는 것은 x값이 아닌, a(기울기)와 b(절편)이다. x값은 수집되어있는 관측치들이 가지고 있는 값을 의미한다.
즉, 우리는 가장 설명력이 높은 '선(Line)'을 구해야하며, 선을 정의하기 위해서는 기울기와 절편 값만 있으면 다른 어떤것과도 구분되는 유일한 1개의 선을 만들 수 있는 것이다.
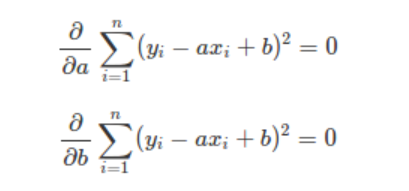
식 (1)을 풀어서 표현하면 식 (2)가 되며,
- 손실함수(잔차의 제곱)을 최소화하는 a(기울기)값을 구하기 위해서는 손실함수를 a에 대해서 미분 ( 식 (2)에서 위에 있는 식 )
- 손실함수(잔차의제곱)을 최소화하는 b(절편)값을 구하기 위해서는 손실함수를 b에 대해서 미분 ( 식 (2)에서 아래에 있는 식 )
하면 된다.
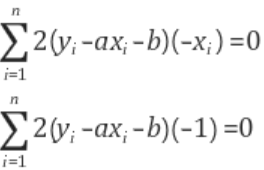
이를 미분하게 되면 식 (3)과 같이 나오게 되며, 위 2식을 연립하여 우리는 a와 b값을 구할 수 있게 된다.
위에서 a와 b를 구해보게되면,
a = { (x - x평균)(y - y평균)의 합 } / { (x - x평균)의 제곱 }
b = y의 평균 - (x의 평균 * a)
이 나오게 됩니다.
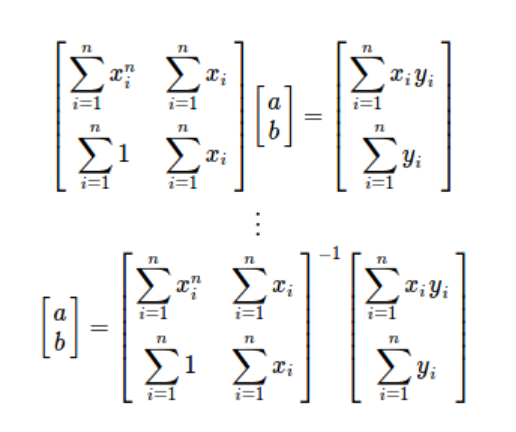
앞서서 알아봤던 방법은 행렬로써도 풀어볼 수 있다.
(i는 각 관측치들을 구별하기 위한 숫자, n은 총 관측치의 숫자)
조금 복잡할 수도 있는 개념이지만, 우리가 실제로 계산할 일은 시험볼때를 제외하고는 거의 없다.
그냥 우리는, 해당 데이터들을 가장 잘 설명해주는(예측력이 가장 높은) 회귀선을 구할때는
" 잔차(실제 데이터와 회귀선 사이의 차이)의 제곱의 총 합이 가장 작은 회귀선을 구한다 " 는 사실만을 인지하고 프로그램에 넣어서 값을 구하고 이에 대한 해석을 하면 된다.
다음 포스팅에서는 파이썬을 활용하여 선형 회귀를 시행해보며, 이번 포스팅에서 미쳐 설명하지 못했던 개념들에 대해서 알아보겠다.
'파이썬(Python), 머신러닝, 딥러닝' 카테고리의 다른 글
| 딥러닝 기초 - (3)선형회귀(평균제곱오차 / Mean Squared Error) / 파이썬 코딩 (0) | 2022.06.22 |
|---|---|
| 딥러닝 기초 - (2)선형회귀(최소제곱법) - 파이썬으로 코딩 (0) | 2022.06.22 |
| 딥러닝을 위해 필요한 3가지 (0) | 2022.06.11 |
| 딥러닝(Deep learning)이란? 딥러닝 vs 머신러닝 vs 인공지능(AI) (0) | 2022.06.11 |
| 파이썬 누락 데이터 제거 (dropna) / dropna / python (0) | 2021.11.26 |




댓글