이번에 알아볼 문제는, 다중분류문제이다.
다중분류 문제란, 타겟(또는 종속함수 / Response)가 여러가지 클래스를 가지는 경우를 말한다.
지난번에 알아본 피마인디언의 당뇨병 예측의 경우, 타겟이 질병유무 이므로, 질병(1) 또는 정상(0)으로만 분류가 된다. 그렇기에,
1)손실함수는 binary_crossentropy를 사용했고,
2)마지막 히든레이어에서 아웃풋 레이어로 전파되는 활성화 함수는 simoid 함수를 사용했다.
하지만, 이번에 알아볼 아이리스 품종 분류 문제의 경우, 타겟이 아이리스의 품종이며 데이터에 제시된 품종은 총 3가지의 품종(setoa / versicolor / virginica)이다.
이진 분류의 경우 활성화 함수의 값이 0.5 이하면 미발생 / 0.5 이상이면 발생으로 분류하였으나, 2개보다 많은 클래스라면, 각 클래스별로 구분되어지도록 만들어주는 선이 더 필요하다. 그래서,
1)손실함수는 categorical_crossentropy를 사용하고,
2)마지막 히든레이어에서 아웃풋 레이어로 전파되는 활성화 함수는 softmax 함수를 사용한다.

소프트맥스 함수의 식은 위와 같으며, 인공신경망이 결과로 내놓은 K개의 클래스를 확률처럼 해석하도록 만들어 준다. 함수의 범위가 [0, 1]이기 때문이다. 따라서 output 노드 바로 뒤에 부착된다.
작동원리의 예시는 아래와 같다.

그렇다면, 파이썬 코딩을 통해서 다중분류 문제를 딥러닝으로 해결하는 방법에 대해서 알아보자
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#분석에 필요한 모듈들을 호출
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
#깃허브 taehojo 님의 자료를 참조
!git clone https://github.com/taehojo/data.git
#분석을 위해 데이터를 df 라는 변수로 저장
df = pd.read_csv('./data/iris3.csv')
#데이터의 구조 살펴보기
df.head()
|
cs |

|
1
2
3
4
|
#species의 종류가 몇개인지 알아보기
df.species.value_counts() #setoa / versicolor / vriginica 각 50개씩
#종속변수가 범주형(Categorical) 데이터이며, 3종류 이상이기에 다중 분류 문제임
|
cs |

|
1
2
3
|
df.info()
#4개의 파라미터는 모두 실수형(float64)이며, 종속변수인 species는 범주형임
#모델에서 계산되기 위해 범주형 데이터를 벡터화 시키는 원핫인코딩 작업을 해야됨
|
cs |

|
1
2
3
4
5
6
7
8
9
10
11
12
|
#X와 y를 나누며, y에 대해서는 원핫인코딩 실시
X=df.iloc[:,0:4]
y=df.iloc[:,4]
y=pd.get_dummies(y)
print(' 데이터 X')
print(X)
print('------------------------------------------------------')
print(' 데이터 y(원핫인코딩 됨)')
print(y)
#데이터 분류와 원핫인코딩이 잘 되었음을 확인
|
cs |

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#모델 구성
model=Sequential()
model.add(Dense(12, input_dim=4, activation='relu', name='Dense_1'))
#Input layer의 노드는 4개(파라미터 개수와 동일)
#Input layer 다음 첫번째 Hidden layer의 노드 : 12
#활성화 함수(Input -> hidden layer1) : Rectified Linear Unit
#해당 Dense의 이름을 Dense_1 으로 명명
model.add(Dense(8, activation ='relu', name='Dense_2'))
#두번째 Hiddenlayer의 노드 갯수 : 8
#활성화 함수(hidden layer1 -> hidden layer2) : Rectified Linear Unit
#해당 Dense의 이름을 Dense_2 으로 명명
model.add(Dense(3, activation='softmax', name='Dense_3'))
#출력층(Output layer)의 노드 갯수 : 3 (setoa / versicolor / vriginica)
#활성화 함수(hidden layer2 -> Output layer2) : 다층 분류 이므로 softmax를 활성화 함수로 사용
#해당 Dense의 이름을 Dense_3 으로 명명
model.summary()
|
cs |

|
1
2
3
4
5
6
7
8
9
10
11
|
#모델 컴파일
model.compile(loss='categorical_crossentropy', optimizer = 'adam', metrics=['accuracy'])
#다중분류(3개 이상 클래스)문제이기에 카테고리컬 크로스엔트로피를 손실함수로 지정
#옵티마이저(경사하강법을 적용하는 방식) : adam(momentum + rmsprop)
#metrics(모델 수행의 결과를 나타내는 척도) : accuracy(혼동행렬에서 구해지는 정확도)
#모델 실행
history = model.fit(X, y, epochs=50, batch_size=5)
#50회 반복 실행
#adam이 sgd 기반이므로 한번에 선택될 batch내 데이터의 사이즈가 5개 설정
|
cs |
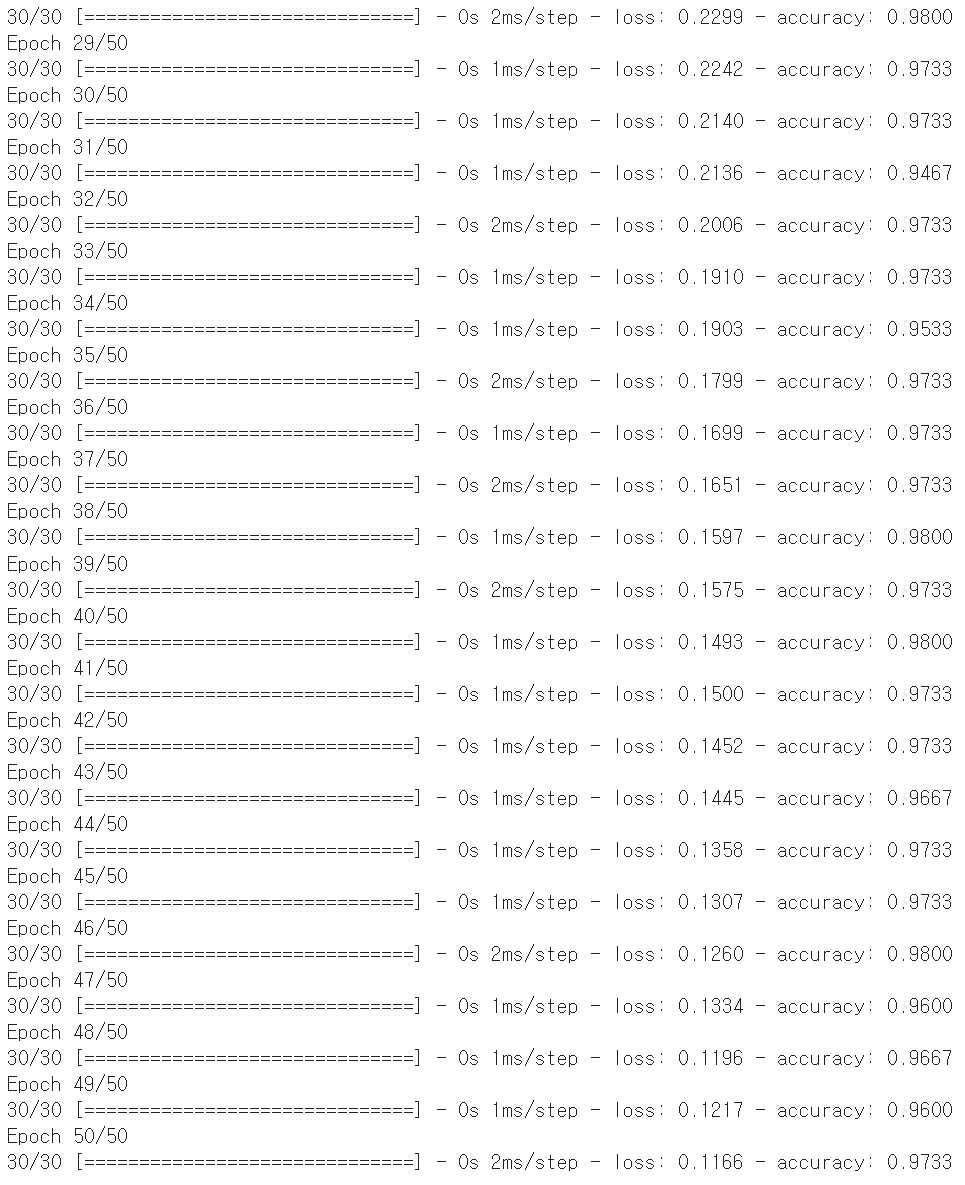
loss 가 점점 줄어들고 있는 것으로 보아 더 많은 실행을 해보아야 할 것으로 판단됨.
accurcy는 0.96 ~ 0.98 정도로 진동하고 있는 것으로 보아 현 시점에서도 꽤나 높은 수준의 분류 정확도를 나타낸다고 볼 수 있음
더 많은 시행을 통해, 최적의 loss 와 accuracy 조합을 찾을 수 있을것으로 기대 됨
'파이썬(Python), 머신러닝, 딥러닝' 카테고리의 다른 글
| 생성형 AI와 다른 인공지능의 차이점 (0) | 2023.04.23 |
|---|---|
| (딥러닝 with 파이썬) k겹 교차검증(k-fold cross validation / k-fold cv) (0) | 2022.08.10 |
| (딥러닝 with 파이썬) 당뇨병 예측(피마 인디언의 당뇨병 예측) - 2) 딥러닝 실행 (0) | 2022.08.03 |
| (딥러닝 with 파이썬) 당뇨병 예측 (피마 인디언의 당뇨병 예측) - 1) 데이터 시각화 (0) | 2022.08.02 |
| (딥러닝 with 파이썬) 폐암 수술 환자의 생존율 예측 모델 (0) | 2022.08.02 |




댓글